


If it quacks like reasoning, should we believe there is actual reasoning going on?
A deep dive into what we can learn from GSM-Symbolic to bring some much needed back-to-basics focus to measuring progress in reasoning with LLMs

If you have more than a passing interest in the (potential) emergence of reasoning skill in large language models, you’re likely to have heard about GSM8K, a widely used benchmark that seeks to assess models on grade-school / primary-school level mathematical reasoning questions.
GSM8K (Grade School Math 8K) is a dataset of 8.5K high quality linguistically diverse grade school math word problems. The dataset was created to support the task of question answering on basic mathematical problems that require multi-step reasoning.
These problems take between 2 and 8 steps to solve.
Solutions primarily involve performing a sequence of elementary calculations using basic arithmetic operations (+ − ×÷) to reach the final answer.
A bright middle school student should be able to solve every problem: from the paper, "Problems require no concepts beyond the level of early Algebra, and the vast majority of problems can be solved without explicitly defining a variable."
Solutions are provided in natural language, as opposed to pure math expressions. From the paper: "We believe this is the most generally useful data format, and we expect it to shed light on the properties of large language models’ internal monologues
Grade School Math 8K Dataset summary, Hugging Face, Nov 2024
Here’s an example GSM8K question to give you an idea
“It takes Tom two hours to walk to work and one hour to ride his bike to work. Tom walks to and from work three times a week and rides his bike to and from work twice a week. How many hours in total does he take to get to and from work a week with walking and biking?”
The questions are designed to be easy for your average human with basic reading and arithmetic skills to answer (as long as they’re not in a rush and don’t get flustered 😛).
In the enormous volume and variety of new work coming out every week in the AI space, I was really struck by the recent preprint from Iman Mizradeh et al, introducing an alternate benchmark they’re calling GSM-Symbolic. In this post, I’m going to dive into both what GSM-Symbolic is, what it can teach us and why I find this work particularly thought provoking.
Leakage and other problems
The greatest challenge with benchmarks today is that the ones which become popular and widely used are, without a doubt, leaking into the data used to train and fine tune new models. The more popular, the more they get used and written about, the more leakage and, unfortunately, the less useful the benchmark becomes for the task of measuring progress.
Why? What does leakage mean? It means that some or all of the questions and answers in the test set of the benchmark have made their way into the datasets that new LLMs are being trained and/or fine tuned on. (Mostly by accident, potentially sometimes deliberately.) This isn’t new to LLMs of course, ‘enhanced’ performance against benchmarks because of data leakage is an age old, vexing problem for any one working in machine learning & AI.
Some folks are guarding against this by creating their own benchmarks that they are careful never to share in a public setting or writeup. But that can lead to a few question marks about transparency in the benchmarking process. So it’s a ‘leaked if you do, doubted if you don’t’ kind of situation.
In the GSM-Symbolic paper, they comment
The GSM8K (Grade School Math 8K) dataset (Cobbe et al., 2021) has emerged as a popular benchmark for evaluating the mathematical reasoning capabilities of LLMs. While it includes simple math questions with detailed solutions, making it suitable for techniques like Chain-ofThought (CoT) prompting, it provides only a single metric on a fixed set of questions. This limitation restricts comprehensive insights into the models’ mathematical reasoning. Moreover, the popularity and prevalence of GSM8K can increase the risk of inadvertent data contamination.
So how does GSM-Symbolic help us?
GSM-Symbolic introduces a templated way to generate variants of the questions in the GSM8K dataset. The symbolic templates allow the researchers to vary the names (e.g. person, currency, food, location) and the numeric values (e.g. 5 apples, 3 hours) that form the ‘window dressing’ of the problem, without changing the mathematical steps required to solve the problem. This alleviates the ‘question + answer’ memorisation we might expect to see through leakage.

The templating also provides a way to systematically study the accuracy impact of changing the numbers or the names in a question and, as we’ll see later, to insert plausibly useful but actually irrelevant information.
The researchers used their templating method to take 100 questions from the GSM8K set and generate 50 new variants of each of those 100 questions. They were able to change just the names, just the numeric values or both at once.
Variable and degraded performance as the questions change
If the models were solving these basic mathematical word problems in a robust, ‘I understand math’ equivalent fashion, we wouldn’t expect that switching from questions drawn from the GSM8K set to questions generated via GSM-Symbolic templates would make any difference to the overall accuracy. Essentially, the math you need to understand isn’t changing, just the ‘window dressing’ of the words that make up the problem.
However we definitely do see a variety of impacts. There are a number of figures that address this in the paper, below is the one I found particularly interesting.

In each model evaluation, we do 50 rounds of asking 100 questions and plot the distribution of answer accuracy that results. Focussing on the bottom righthand plot for Mathstral-7b-v0.1 by way of illustration, we see that on the original GSM8K questions Mathstral-7b-v0.1 got 80% correct. On the 50 sets of template generated GSM-Symbolic questions, the accuracy of the same model varied from around 65% to 80%.
(Note that GPT-4o is doing a substantially better job than any other model pictured here, in accuracy and in spread of results, as the x-axis scales are not the same.)
The fact that for many models (21 out of the 25 tested), the accuracy on the original GSM8K questions falls well to the right of the performance distribution mean indicates that leakage of the benchmark question set may well be distorting published accuracy claims for models on GSM8K.
For me, the variation seen across all models on the 50 trials is an even more interesting finding considering that the questions in each trial are mathematically the same, just with different names and numbers. This is certainly very suggestive of fragility in the ‘mathematical reasoning’. The paper dives into this further with an analysis of the impact of changing just the names in the question, just the words in the questions or varying both together. In general, the more you change the ‘window dressing’, the more the model performance degrades, exactly what you don’t want to see when you teach kids mathematics as you want evidence that they are learning translatable fundamentals not patterns.
Irrelevant information gums up the works badly
The real mike drop moment for me though when reading the paper was in the section on GSM-NoOp.
We introduce GSM-NoOp, a dataset designed to challenge the reasoning capabilities of language models. To create the templates, we add seemingly relevant but ultimately inconsequential statements to GSM-Symbolic templates. Since these statements carry no operational significance, we refer to them as "No-Op". These additions do not affect the reasoning required to solve the problem.
Below is an example of what happens when these statements with no operational significance are introduced into the question text. (If you are a New Zealander, try to overlook the misuse of our national bird as a fruit)

What happens to accuracy when you feed questions containing this type of irrelevant information into the large language models? It drops a lot!
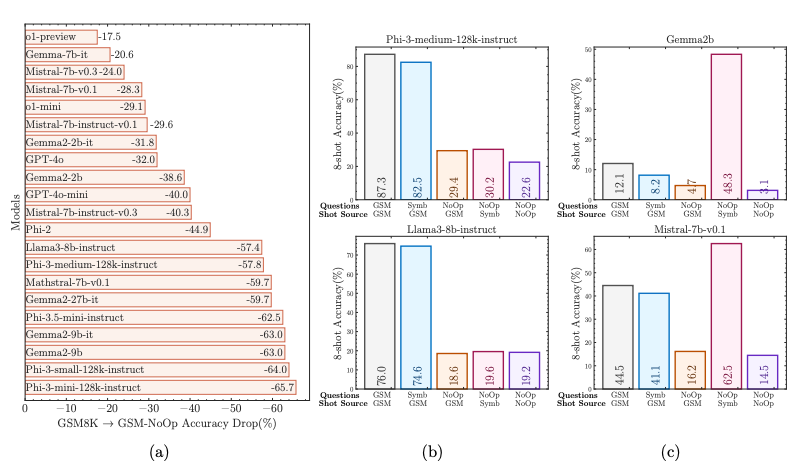
Now there is a HEAP going on in this figure so bear with me as we step through it.
Focussing first on sub figure (a), we see that when you feed simple math questions which also contain related but irrelevant data about details NOT impacting the reasoning steps required, performance drops across the board. OpenAI’s flagship o1-preview model copes best, but even there we see the answer accuracy drop from 95% to 77% (this shows up in the figure as the -17.5% accuracy drop depicted in the top bar, my rounded accuracy numbers come from the comprehensive stats table in the appendix of the paper
If you’re not conversant with the details of shots in model prompting, you might want to skip on to the next section here. For those who are, lets take a closer look at sub figure (b). As explained in the paper, for almost all the experimental runs, the authors have been using an evaluation prompt format with 8 shots and chain-of-thought-prompting where the questions in shot examples are drawn from GSM8K.
The central tan bar, in sub figure (b) is the accuracy on questions containing the irrelevant ‘NoOp’ info, with 8 shots of original GSM8K questions. As the paper details
Hence, each shot provides the required reasoning steps. The target question from GSM-NoOp then presents yet another variation of the same question that is different only in values and the added clause that is inconsequential. This setup should simplify the task by making it clear that the extra information in the target question is irrelevant. However, as shown in Fig. 8b, the performance remains within the standard deviation, even with 8 shots of the same question providing the reasoning chain.
In the magenta bar, the 8 shots are eight different wording variants of what is mathematically the same question but with no irrelevant info. In the lilac bar, the eight shots are all generated from symbolic templates with ‘No Op’ info inserted. So we’re telling the model eight times that a correct answer should ignore the irrelevant information. Does it figure out to do so? Sadly not.
If you want to understand what’s going on in sub figure c, go read the paper 😎
So what?
This is a fascinating paper and I really encourage you to read it through end to end yourself. In the conclusion, the authors state
The introduction of GSM-NoOp exposes a critical flaw in LLMs’ ability to genuinely understand mathematical concepts and discern relevant information for problem-solving.
Adding seemingly relevant but ultimately inconsequential information to the logical reasoning of the problem led to substantial performance drops of up to 65% across all state-of-the-art models.
Importantly, we demonstrate that LLMs struggle even when provided with multiple examples of the same question or examples containing similar irrelevant information.
This suggests deeper issues in their reasoning processes that cannot be easily mitigated through few-shot learning or fine-tuning.
I would agree.
And a clear illustration of this limitation is the very best way to guide the next round of research so it should be both sought after and celebrated. Not seen as negativity or sour grapes but as an integral part of a robust research & development process.
Warning, minor rant follows.
Why did this paper stand out for me on first reading and then stick around in my head for weeks afterwards? Frankly because it both saddens and worries me that this type of research needs to be done by an independent team at all.
Leakage is well understood as a challenge, so is pattern matching.
So this paper represents a well executed but obvious critique of a very bold claim - the emergence of robust mathematical reasoning in artificial intelligence.
When I was a practicing scientist (yes that was a while ago), you did your darndest to falsify your own results BEFORE you published them. (Infinitely preferable to having someone else point out the error of your ways later.) Scepticism, bordering on outright suspicion, about anything that seemed too good to be true was, well, just an integral part of doing science.
The drive to deploy new models and claim new breakthroughs seems overwhelmingly high at present. And hence we’re all ending up mired in a sea of results that might be true …but just as easily might not.
It’s enough to want to make you stick your head under your pillow for a year and see what’s still standing at the end of it.
On a more practical note, I encourage you all to use this accessible work by a well regarded team to illustrate to those around you who may need reminding - be that your team mates, your fellow executives, your investors or your board members - that good science and good product development takes patience, scepticism and a willingness to kick the tyres hard even on those ideas that seem oh so very compelling and commercially attractive.
Till next time
A warm welcome to the 74 new readers who have joined since my previous post, an equal parts gratifying and mortifying number because it makes me feel bad for not writing more often! I’m striving to get back into a more regular cadence for publishing and am seeking inspiration, so if you have a topic you’re curious to know more about please get in touch.
Summer is still struggling to really get into gear here in Victoria but a dry season lies ahead of us for sure as the dams never got back to full on the farm. Picture me trying to water several hundred small trees by hand as temperatures soar …