


Sweet spots for reasoning models
What they excel at, where they struggle and what that might mean

I’ve been thinking a fair bit about benchmarks recently. They feature prominently in new model announcements and when they saturate they get gushed over by the semi technical popular AI press. They’re also critical to meaningful progress, unglamorous to construct and not a great proxy for useful model capability in the real world!
If you are working to construct useful generative AI based capabilities in your own products, you will need to think very hard about meaningful evaluation of those capabilities, both during construction and during operation. You won’t learn a lot from the scores of given models on given benchmarks. But as it turns out, you can learn quite a bit from diving into the ins and outs of thoughtful benchmark construction.
BIG-Bench Extra Hard
The folks at Google DeepMind have been at it again with the third iteration of BIG-Bench, BIG-Bench Extra Hard released in Feb. The accompanying paper is another one of those big reads where much of the useful nitty gritty detail is to be found in the appendix and I’m going to dive into the aspects which I found the most thought provoking rather than provide a comprehensive review (as always, if this is interesting I encourage you to read the very accessible paper to learn more).
The intent of all the BIG-Bench work has been to “understand the present and near-future capabilities and limitations of language models”. The problems in the benchmark are diverse and try to cover areas as disparate as spatial reasoning, linguistics, movie recommendations, common sense, mathematics and the rules of sports games.
Recent research has made significant strides in evaluating the reasoning capabilities of large language models (LLMs), but the focus has been disproportionately skewed towards math/science and coding. This emphasis is likely driven by the availability of challenging benchmarks in these domains and the relative ease of evaluating quantitative solutions.
However, reasoning encompasses a far broader spectrum of cognitive skills, including logical deduction, temporal and spatial understanding, commonsense reasoning, and even the ability to comprehend humour.
The paper authors don’t mention it, but I think that the over representation of mathematics and coding applications and demos for generative AI models in general and ‘reasoning’ models in particular will be due in part to the backgrounds of the folks working on the models and pulling together the demos. It’s pretty natural for humans to play to their own strengths.
As an aside, the original BIG-Bench, where BIG stands for ‘Beyond the Imitation Game’ which was published in June 2022 had 450 authors. This is complex and multi disciplinary stuff.
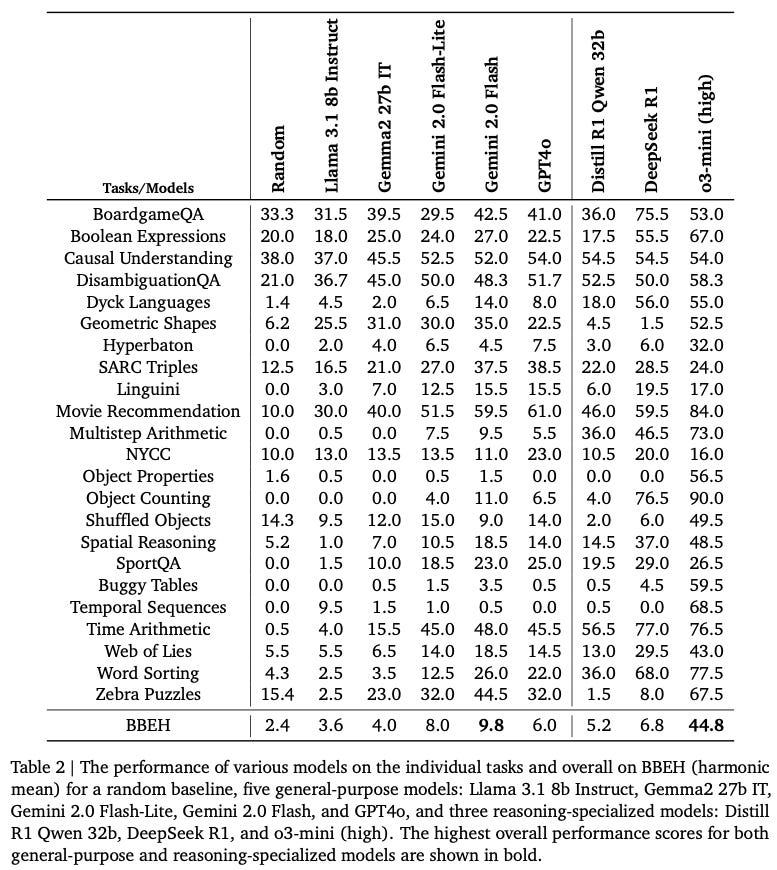
The table to stare at
Long time readers will know I often write to force myself to read more deeply. Table 2 in BBEH is one of those illustrations which will repay a LOT of pondering. I’ll refer to it regularly in what follows. Take a good look now and prepare to scroll back often.
Guessing can get you a long way
Perhaps the most eye opening thing for me in reading the BBEH paper was just how high the ‘random baseline’ performance was on some of the tasks. It’s obvious as soon as you stop and think about it but let’s be honest, we often don’t.
To be useful, benchmarks need to provide quantitative measures and that pushes them towards questions with precise answers. But precise answers can also lend themselves to categorical answers: yes / no, true / false are the obvious ones. Suddenly, boom, you have a high random baseline, 50% in the case of a binary answer set. It might still be super challenging to reason towards the correct answer but as any one who has sat a multiple choice test will tell you, if it doubt, guess.
I refer you to Table 2 where the random baseline varies from 0 for some tasks to a whopping 33% for the task BoardgameQA. Digging deeper into this one, it isn’t that the task is easy (it definitely isn’t!), it’s just that there are only three answers.
The final answer to the question is either ‘proved‘ (if the statement in the question derives from the theory), ‘disproved‘ (if the negation of the statement in the question derives from the theory), or ‘unknown‘ (if neither the statement in the questions nor its negation derives from the theory).
Yes, a tad wordy - in summary the options are proved / disproved / unknown.
This is really going to stick with me. The first question to ask when you see model performance against a novel benchmark - what is the random baseline performance? In many cases it will be higher than you intuitively expect.
As a side note, it’s interesting that the BoardgameQA task is the only one where DeepSeek R1 really blows o3-mini (high) away. Don’t ask me why.
Comparing general purpose models with specialised reasoning models
Stare hard again at Table 2. On the left hand side we have random baseline and five ‘general purpose’ LLMs. On the right hand side, we have three ‘reasoning specialised’ models.
Anyone who has spent time trying to make an AI model perform just a little bit better at task ‘X’ will be familiar with the balloon squeezing nature of this exercise. Optimise for one outcome and you almost invariably end up compromising performance in another area.
While it isn’t being talked about much, the test time compute models are better at a fair few things but they are not better at everything across the board. Figures 5 and 6 in the BBEH paper illustrate this nicely.

Which brings us back again to the important point that AI models in general and the reasoning models in particular are currently stronger at tasks with clear answers. It isn’t a surprising point but I worry that it is often lost in the noise of the general enthusiasm that currently surrounds an interesting, useful but of course limited tool.
We observe that the tasks that gain the most are those involving counting, planning, arithmetic, and data structures and algorithms. Whereas the tasks that gain the least (or sometimes negatively) are mostly those involving commonsense, humour, sarcasm, and causation.
Our results indicate that reasoning models achieve the most significant gains when applied to formal problems and demonstrate limited progress in handling the softer reasoning skills which are typically needed for complex, real-world scenarios.
Reasoning models fail to see mistakes
The mysteriously named Dyck Languages task is an absolute goldmine of interesting things to think about. In case you, like me, did not know what a Dyck language is, a brief refresher.
In the theory of formal languages of computer science, mathematics, and linguistics, a Dyck word is a balanced string of brackets. The set of Dyck words forms a Dyck language. The simplest, Dyck-1, uses just two matching brackets, e.g. ( and ).
As an example, ()() and ()(()())()(()()) are both elements of the Dyck language, but ())(())( is not.
The Dyck Languages task in BBEH “involves finding the first mistake in an existing chain-of-thought sequence used to answer a Dyck Languages question”. The correct answer in each case is EITHER the step in the CoT sequence where the first mistake occurs OR that there are no reasoning mistakes in the sequence. As you can see below, LLMs do poorly at this and while the reasoning models are, as you might expect, a big step up, they are still not doing well at all.

For the traces where this is a mistake, the models can fail at the task in a number of distinct ways. For instance, they can (a) mis-classify a correct reasoning step as incorrect before any error has occurred or they can (b) miss the first error but identify a later erroneous step correctly.
We find that the majority of the errors belong to the second category. Specifically, for o3-mini (high) 98.7% of the errors belong to the second class, for Gemini 2.0 Flash all the errors belong to the second class, for Gemini 2.0 Flash-Lite 94.9% and for GPT4o 96.8% of the errors belong to the second class.
So, at least for the frontier models tested, it appears that they are way better at identifying correct reasoning steps than they are at identifying ones that have errors.
Humour is hard
Now many humans, myself included, are definitely not cut out to caption cartoons. But look more closely at this task (Table 2, NYCC) and you realise that we’re not asking the model to write the caption but to identify which in a set of ten human created captions is actually funny.
I love the ingenuity behind this task creation and it certainly highlights why so many folks were needed to pull together the BB task set in the first place. Who knew that the New Yorker manages to get thousands of people to engage with creating cartoon captions?!
To make the task significantly more difficult, for each contest we sample one query from the top ten rated, and then take captions ranked 1000-1009 and ask the model to choose the funniest.

GTP-4 Turbo looked like it was doing really well on the original BB variant of this task (“choose the funnier of two captions”) getting a roughly 70% accuracy … against a baseline of 50%.
However with ten plausible options to choose from the accuracy plummets.

Oh, you want to know which of the captions above readers of the New Yorker thought was actually funny? It’s caption number 9.
A truely great benchmark question also sparks other avenues for exploration and other ah ha moments on why ‘AI all the things’ thinking can be so accidentally naive. I’m now curious to see multi-modal performance on the direct problem of image to caption humour identification rather than via textual scene description as is done here. And if humour is so tough for a model to identify in the (relatively) homogenous population of New Yorker readers, what are the implications for models understanding the humour of diverse cultures? Or the humour of a particular, rapidly forming sub culture?
SARC Triples
In a similar vein, the low scores (not much boost over random) for SARC Triples, a challenging sarcasm detection task are both intriguing and worrying. As I write this, the US Govt appears to be seriously considering revoking visas based on AI analysis of social media posts. And yet AI clearly fails to understand humour in general and sarcasm in particular.
Maybe you have to play the game to know the game
If you’ve played Trivial Pursuit, you’ll know the agony of getting that last wedge of cheese. Everyone had their atrocious category, mine was orange - Sports & Leisure. But don’t let the task name fool you, that’s not the idea of SportQA at all.
SportQA (Xia et al., 2024) is a challenging sports understanding dataset designed to test rule-based and strategic reasoning capabilities in LLMs beyond surface-level sports knowledge. It consists of three levels (Level 1 to Level 3) with increasing difficulty. In this work, we focus on Level 3 questions, which are curated by coaches and student athletes across six sports: soccer, basketball, volleyball, tennis, table tennis, and American football.
Expert student athletes can answer these Level 3 questions with near-perfect accuracy. Disembodied models not so much.

Interesting to note here that while by design these are problems that need strategic reasoning capabilities, the reasoning models aren’t yet opening a significant gap over the plain LLMs.
In summary
For me, the BBEH paper highlights beautifully why benchmarks saturate, why evaluations are hard and why both are vital. I hope I’ve prompted you to look with a much more scientific eye at both benchmark composition and granular model performance across tasks.
I resisted the temptation to go on and on with this as I don’t want the post to be unreadably long! The way the various models make mistakes is really, really interesting and the big differences in performance for models across the tasks is deeply intriguing. Even o3-mini (high), which is clearly doing the best overall, struggles in places that make me want to know much much more.
Place these challenging questions right at the front of your mind whenever you are thinking about using Gen AI based models in an important, real world decision making context. True edge case AI failures will be with us forever and it’s likely that given time the rest of the world will learn to adapt - workflow wise, legally and morally - as we have with other technologies.
However from a deep dive into just this benchmark, we can see that we’re not yet even close to edge cases being the predominate way a model fails.