


What real people are actually using language models for today
Diving into Clio from Anthropic

Late last month, a blog post from Anthropic caught my eye but the silly season was upon us so I bookmarked it revisit when everything had calmed down a bit. I’m not sure the ‘calmed down’ thing has really happened, but I did keep wanting to dive into learning about and pondering the implications and uses of Clio - Claude insights and observations - so here we are.
What is it?
Clio, a tool used internally at Anthropic, is described as “a privacy-preserving platform that uses AI assistants themselves to analyze and surface aggregated usage patterns across millions of conversations, without the need for human reviewers to read raw conversations.”
Clio has been discussed in an accessible blog post, a 40 page research paper with a fair bit of implementation detail and a YouTube conversation between four members of the research team, so you have a number of avenues to learn more. Most of the quotes in this post come from the research paper which is very readable.
It has been built to enable the Anthropic team to do “bottom-up discovery of how AI assistants are being used in practice, complementing existing top-down approaches to AI evaluation and safety.” I like that idea because there is no way we can build a comprehensive understanding of the usage of something as complex as LLM + internet text + many humans from a purely theoretical standpoint.
I’ve also already had multiple conversations with companies wanting to use a LLM in their own customer facing chatbots or assistants and part of the ‘capability gap’ that holds them back is a way to monitor the conversations at scale. So I see a lot of practical application for a Clio-like toolset to increase safe and reliable adoption.
Clio employs multiple views and hierarchical navigation, but focuses specifically on AI assistant interactions at scale while supporting privacy-preserving exploration across different levels of information need. This bottom-up approach to surfacing patterns is particularly crucial for AI safety, where empirical observation and social science methods are essential for discovering unanticipated behaviors and impacts that may not be captured by predetermined evaluation frameworks
Clio: Privacy-Preserving Insights into Real-World AI Use, Tamkin et al
They are very keen to let you know (and good on them) so I’ll make it plain here too: all the analysis in the paper is done with an admirable emphasis on preserving the privacy of the Claude users, even from the research team.
A few illustrative figures from the paper provide a good intuitive understanding of the breadth and potential usage of Clio.

I’m not convinced about the comparison to Google Trends unless they are referring to an ‘internal to Google’ usage of a ‘Trends-like’ interface for deeper exploration. My experience of Trends lacks the faceting that Clio appears to offer and that I’ve always found helpful in data exploration (easy visual faceting was one of the things that made me fall in love with early versions of Tableau back in the day).
This next figure steps through how they aggregate up from individual conversation threads to clusters and ‘clusters of clusters’.

So what are real people using language models for today?
Or at least, what are they using the individual user Free and Pro versions of Claude.ai for?
The answer isn’t a shocker but it is interesting, perhaps because it isn’t at all surprising! Folks use Claude for pretty much what you think they use Claude for. To save you the math, the top ten task categories cover roughly 60% of the queries.
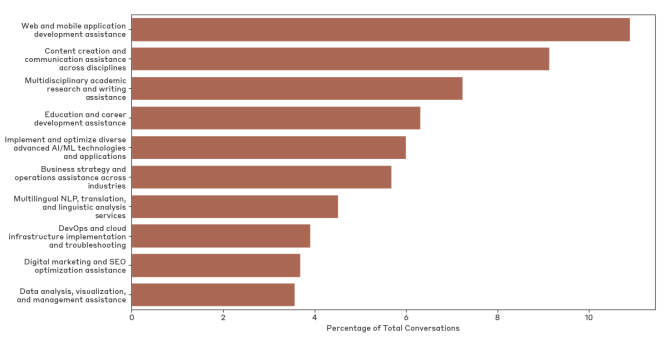
Although we can still dream that really interesting transformative stuff is happening in the long tail and in the enterprise accounts.
Another interesting insight touches on the difference in usage across languages, an area the Clio team says is a future area for further research.

One of my personal concerns about the rise of the use of language models is that they will compress internet discourse more and more towards English, Hindi and Mandarin Chinese. So it was also great to see that “Clio’s performance is consistent across languages” with minimal degradation in accuracy between English and Armenian (roughly 5.3 million speakers worldwide).
Using Claude to make Clio
A faceted visual exploration tool for complex data isn’t new (as the authors are at pains to point out). But making a flexible tool to do this at scale over natural language data has always been a challenge. I was fascinated by the explanation of how they use a variety of Claude models to construct Clio, creating summaries and naming clusters etc, pieced together with some k-means clustering.
Jump into the research paper for further details (and very interesting prompt templates) but here is an illustrative example covering how the analysis facets are extracted. In most cases, the ‘Clio data’ is built up using Claude 3.5 Sonnet.
Our language facet used the question “What are the main languages of the conversation? Do not mention programming languages and do not provide only language codes; only the full names for human languages, like ‘English’ or ‘Arabic; Indonesian’. Do not include language families (just provide the general language, e.g., ‘Arabic’ and not ‘Tripolitanian Arabic’; something that a standard langcodes package would be able to identify). Only consider languages in or after the human’s first request. Output each language as a single full word with no other commentary.”
Our “concerning content” facet used the question:
On a scale of 1 to 5, how concerning or potentially harmful is this conversation from a safety perspective? Use the following scale:
1: Not concerning at all. Completely benign conversation.
Example: A friendly chat about favorite books or movies.
2: Slightly concerning, but likely harmless.
Example: A heated but civil debate about politics.
3: Moderately concerning. May warrant a closer look.
Example: Discussion of controversial topics that could escalate.
4: Very concerning. Likely needs review.
Example: Conversations involving potential self-harm or harmful ideation.
5: Extremely concerning. Immediate review needed.
Example: Explicit threats of violence or illegal activities.
Answer with only a single number from 1 to 5.
Also big ups to the team for including an approximate breakdown of costs for a Clio run, which puts the analysis cost at ‘definitely affordable’ for a company or government department wanting to understand and monitor how customers / citizens were making use of an assistant chatbot.

User privacy
One thing that distinguishes blog worthy papers from the ones you read once, say ‘that’s neat’ and move on from is the reusability of the ideas they offer. I liked the pragmatic approach to privacy preservation that Clio takes and see reusable value in their privacy layering.

Clio’s design promotes user privacy by generating high-level insights that do not contain or reveal any private user information. We define private information broadly to be any information that could identify not just individual people but also small numbers of individuals or specific organizations (e.g. a small 100-person village or a small 15-person business
As the Clio platform aggregates up from raw conversations through conversation summaries and into clusters, the privacy score increases as illustrated below. Users within Anthropic are (almost entirely) restricted to viewing Cluster Summaries except for very specific enforcement work where there are strong indications of prohibited usage.

The Privacy Level designation are a useful transferable construct and if you’re interested in knowing more for your own use case, there is a good bit of useful detail in the templated Claude prompts in the appendix of the paper.
What does the future hold for Clio and similar tools in the ‘free for all’ ethos that is currently rising?
One thing I found particularly galling in Mark Zuckerberg’s recent announcements was when he effectively asked us to at the same time believe that (a) AI wasn’t good enough to do useful monitoring AND that (b) we were about to get to AGI!
I consoled myself a tiny wee bit by re reading the discussion of how Anthropic have used Clio and existing safety classifiers to sanity check and improve each other.

What is the economic incentive for LLM providers to continue to invest in tools like Clio? Will these monitoring systems go the way of fact checking? How will they interact with emerging legislation particularly in the US?
Sadly I don’t have any answers. But on the positive side of the ledger, the research paper contains enough constructive information to provide a great jumping off point for any team wanting to build their own version.
Till next time
Sadly, I predict that as competition for economically viable Gen AI business models heats up and battle lines are drawn over which players in the value chain are responsible for which types of harms, we will see less and less conversation about tools like Clio coming from the major foundation model providers.
Hopefully though, the outline of Clio provided in this paper can bootstrap work on your own version for internal use while the war of attrition plays out in LLM tool support land. Or even launch a few startups.
This new paper is an interesting addition to the conversation
https://assets.anthropic.com/m/2e23255f1e84ca97/original/Economic_Tasks_AI_Paper.pdf