
How do you access reliable information in the age of Gen AI?
And will the internet as we know it survive the experiment?

As a kid, I read a lot of Sci Fi. So the idea of a super powerful ship-board computer that can instantly answer any of my questions is certainly deeply ingrained in my fiction filled psyche. I think it is with a lot of folks. However, one thing all of those books lacked, is any mention of the commercial model that enabled the development of those fabulously helpful (and presumably fabulously expensive) super personal assistants. There was never a whisper of a biased answer, a historically inaccurate representation of past galactic history, an echo chamber of polarised views or the clarification of a faulty presupposition (al la ‘Have you stopped smoking?’). These computers were perfect, unsullied by commerce and we never had to observe the painful process of how they got to be that way.
Partially because of Sci Fi novels, TV shows and movies, I reckon we’ve got a collective blindspot that’s hindering sensible conversations about
(a) whether it is in fact possible to build an endlessly helpful and all knowing AI and
(b) how on earth the commercial reality of building and operating such a thing wouldn’t so utterly, massively skew the incentives of those building it that we either
further entrench and widen the gap between the global haves and havenots via gated access or
set ourselves on the road towards an ad-driven, preference-pandering, consumption bubble the likes of which we have never seen.
Or both of course.
These are ideas I’m very much pondering and prodding at the moment, so sadly don’t expect any answers in what follows. Hopefully though you’ll gain some insight into good questions to be asking of yourself and others. And heads up that this is a bit of a darker post than my usual. Must be the phase of the moon.
Letters from the past informing the future
I was started down this particular rabbit hole by an episode on Freakonomics Radio diving into whether Google Search results are actually getting worse or we’re all just getting jaded. The whole episode is interesting, this particular piece is almost an aside to the narrative but it really stuck with me.
Mayer is Marissa Mayer, of Yahoo fame, the 20th employee at Google and she was involved in the very early conversations about whether to run Google Search as a subscription model or as ad-sales model. (Note that C.P.M in the quote below means ‘cost per thousand’ for mildly esoteric reasons. And the original conversation was recorded around 18 months ago so Mayer is referencing the Q4 sales circa 2022.)
MAYER: So we were like a $10 C.P.M., a penny per page. And we were like, “Well, we think people are going to start doing more search, not less. And as people start doing searches, let’s assume they do 20 searches a day, five days a week, they take the weekends off. That’s 100 searches a week. And there’s 52 weeks in a year. So that’s, you know, 5,200 searches, which means if we could do a $10 C.P.M., we could make $52.”
So then you’re like, well, wait. That means with ads, we could probably make $52, where consumers are really putting a value on this that’s closer to $20, right? So it’s two and a half times as lucrative to do it as ads, as monetizing the consumer directly.
And by the way, in Q4, in the retail quarter, in the run-up to Christmas, the C.P.M. that Google sees in North America today, I would guess is well north of $100 C.P.M. So it’s not a penny per page. It’s a dime per page.
So then you’re saying, well, now it’s the difference between, like, the user might pay us $20 or maybe because of inflation and time, maybe now they pay us $100 a year. But Google can make $500 a year on those same searchers with that same set of assumptions.
DUBNER: So in the end, it was not a hard decision.
MAYER: It wasn’t a hard decision.
Is Google Getting Worse? (Update), Freakonomics, Radio Episode 522
To summarise: we went ad-based because, even back then, we could see that the upside was way more lucrative.
With this rolling around in my head, I sat down to dive into two papers I’d had queued up for a few weeks, both co authored by the ever thought provoking linguist Emily Bender with her colleague Chirag Shah.
The first Situating Search is from March 2022, a good seven months before ChatGPT launched. The second, Envisioning Information Access Systems: What Makes for Good Tools and a Healthy Web? is fresh off the press. (All quotations below, unless otherwise stated, are drawn from one paper or the other. Emphasis is mine.)
You can of course read these papers as yet another rant from disgruntled linguists whose horse didn’t win the race. Or get all caught up in your own hubris and just be rude, as Sam Altman was with a similarly sceptical piece from Gary Marcus that dates from around the same time. No prizes for guessing that’s not my take.
Rather, my one line summary of two great papers which are well worth your time to read in full is
‘Even if we can, doesn’t mean it is at all a good idea!’
If we continue to build systems as if we’re on the cusp of building something straight from the movies, we may get ourselves instead to a very dark place. Better to reorient ourselves around what need we are building to fulfil and dispassionately examine the best road to get there.
Or as Bender and Shah put it.
(T)his is also the time when we must ask again - what is it that Information Access users really want, do the new modalities and interactions address all their needs, and how do they impact society as a whole?
If we optimize towards some imagined ideal, perhaps one inspired by science fiction representations of ship-board computers, we fail to design for actual users in the actual world.
In other words: the goal of Information Retrieval should not be to get users the ‘right’ answer as quickly and easily as possible, but rather to support users’ information access, sense making, and information literacy.
We also need these systems to provide exposure to such diverse and more comprehensive information as is available, as well as be mindful of societal context of fairness, equity, and accessibility.
In search we trust … but for how long?
I’m sure that you, like me, use a search engine of one ilk or another almost every day.
How cold will it be at the mountain on the weekend? What’s a tasty cake recipe that uses carrots and walnuts? Can I safely destroy a wasp nest myself? How do I enable Night mode on my Mac? Where can I buy dehydrated meals for hiking?
But how did you parents search for information? Or your grandparents?
Prior to 1980s, people often went to a search expert, viz. a librarian, who would connect them with relevant information based on a brief interview. That interaction style changed as large amounts of information went online and started getting connected with the World Wide Web.
Search engines emerged that allowed even a novice to search through large amounts of information with a few keywords — without knowing a specific query language or waiting for long.
We are still living with this model as the most prominent way of searching.
However, with the emergence and ever-growing popularity of social media services, searching also became more social. Question-answering platforms gained enormous success with hundreds of millions of users asking and answering questions through social and community Q&A services.
Information became a commodity that could be traded for engagement, driving people to contribute, rate, and comment more.
Searching is no longer only about finding relevant information from a few select sources. Since almost anyone can produce and disseminate information, knowing who created information and with what agenda became increasingly important for finding useful and trustworthy information.
As Bender and Shah discuss, there are two primary way that one can access information - directly or with algorithmic mediation.
Using a search engine that provides a ranked or organized set of results, or browsing through recommendations on a media app are examples of information access that are algorithmically mediated.
As the extent of algorithmic mediation increases, and the returned information becomes narrower and more apparently tailored (think moving from a ranked set of search results to a pithy one paragraph ‘answer’), the agency of the human doing the searching and the transparency of the relevance and suitability of the answer decreases.
(W)hile the user loses some level of agency going from direct information access to mediated access, they still retain enough of it to be able to drive the process, question the outcomes, and find alternatives. All of these are put in jeopardy as we look at the newest and increasingly popular form of InformationAccess (IA): generative IA.
By definition, this falls under algorithmically mediated IA, but while typical algorithmic mediation happens for matching, ranking, and organizing existing information, GIA involves synthesising text based on information about word distributions and sometimes fine-tuning with supervised training data pertaining to human preferences.
The result is text that might even be taken as new ‘information’, despite the fact that the systems lack any world model or understanding of the text they manipulate.
Reading these papers has really crystallised for me how much my usage of search on the web for the past two decades or more has relied on a strategy of ‘trust but verify’ and how much of that verification has been done subconsciously by absorbing the information that surrounds the information I was after - frequency of occurrence, websites I recognise, authors, journalists and colleagues I trust.
Without this peripheral data - very little additional information is provided by ‘chatbot style’ interfaces, styled as they are consciously or unconsciously on oracles - and in the face of a rising flood of generated content, what happens to my information curation beliefs?
Is a chatbot style interface useful if I need to constantly verify the information provided with a quick google before use? Would I, over time, come to rely on the oracular output without verification? How long before that ended badly?
Of course I could trust in the market - either these will get good enough to actually be useful, or they will fade away as other fads have. But what damage might accrue in the time being?
Synthetic media spills and the destruction of provenance
There is a section in Envisioning Information Access Systems that speaks about the web as ‘an endangered information ecosystem’ and how the synthetic media generated by LLMs and their visual media equivalents are polluting this ecosystem. It’s an evocative and arresting metaphor.
An ecosystem is a collection of interdependent entities standing in relationship to each other.
On the Web, one key type of relationship is that between information providers and information accessors. In this relationship, information accessors desire to find information sources they can trust; information providers desire to show themselves to be trustworthy.
Synthetic media break these relationships of trust and trustworthiness, making it harder for people seeking to access information to find sources that are trustworthy - and eventually to be able to trust them even if they have found them.
This disruption of trust began even with simpler forms of synthetic media than LLM-powered chatbots, when search engines switched from providing sets of links to extracting (or abstracting) snippets of text from search results or automatically populating answer boxes.
These snippets, even when they are simply extracts from the underlying page, are synthetic media in the sense that the search engine is juxtaposing them to the query and asserting a coherence relation of ‘answer’ between the two.
There are now numerous reports of AI enabled content generation causing grief. From parasitic ‘companion texts’ on Amazon, to fake journalists, fake quotes, low quality ‘answers’ on Q&A sites and of course exploitive pornographic and CSAM deepfakes. In addition to causing significant personal harm to individuals in many cases, all of this is ‘gumming up the works’, making it more difficult to be confident of anything you find online, putting a higher burden on individuals and responsible companies to verify and filter any and all data they use.
A disturbing sign of things to come - reasonably innocuous but nonetheless, synthetic and hence non-factual images have been filtering into Google Image search results. Simply because they have been widely shared and are hence being picked up in by algorithmically mediated processes that organise the ‘information’ on the web. Page rank is starting to backfire badly.
As Rich Felker puts it on Mastodon
I think a lot of ppl who are skeptical of the criticisms here really don't understand how it's *burning* anything because they haven't thought about how value is derived from provenance.
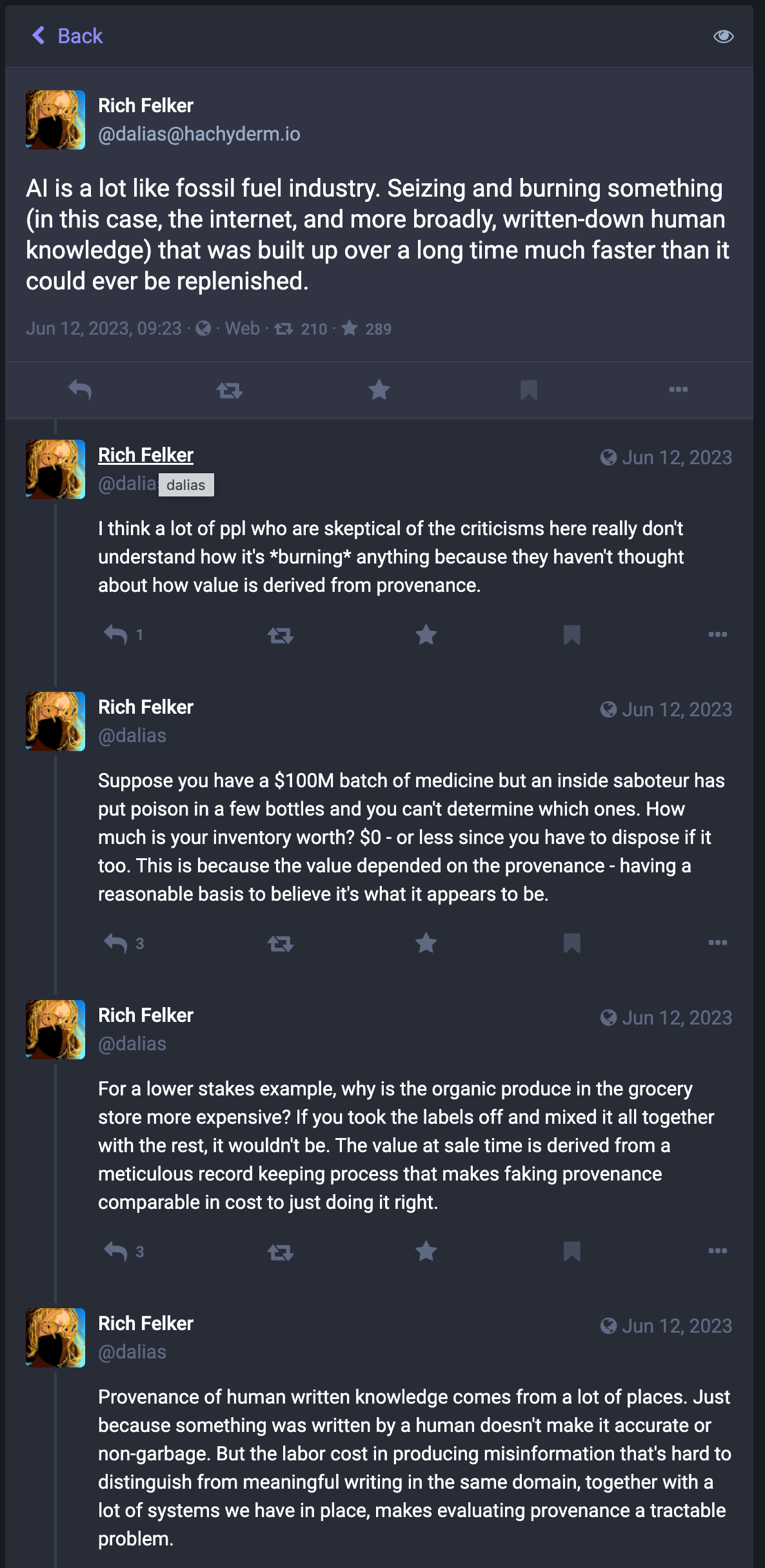
Once you can’t tell whether something on the web was written by me, or written by Generative AI that sounds like me, what are you supposed to do? Call me up to check what my opinion on something is?
I love the web and I use it A LOT. This feels like a crisis point - we need once again to save ourselves from ourselves.
Where to from here?
I’m coming up empty on what seems like the biggest challenge - what is a commercial model that doesn’t lead to algorithmic rent extraction and enshittification?
So I’ll lean once again on Bender and Shah, who present a collection of questions intended to inform potential research directions.
How can we support users in learning to identify and contextualize synthetic text?
How do we fashion IA systems that are understood as public goods rather than proit engines? Are there distributed peer-to-peer conceptualizations that would support this, even without massive public investment?
How might we structure IA systems such that there is shared governance structures that could slow or resist the injection of hateful content or other misinformation?
How can we detect potential biases in responses generated by an IA system? How can we mitigate them or position system users to mitigate them?
In working to mitigate bias in IA systems, how do we navigate tensions with measures of relevance and other desirable characteristics?
How do we balance summarization, which provides access to information across very large data collections, with transparency into the sources of information and its original context?
To which I will add my own: how do we create the space and funding for smart folks to work on all of the above?
So much to do and to hope for. This space will never be a boring one to work in!