
ARC - benchmark, challenge, prize
What it is and why you should care

A surprising and intriguing thing that has emerged from the white hot hyper focus on AI in the last two years, is how little we know about and agree on what intelligence is and how to measure it.
Indeed, one of the hallmarks of AI development over the years seems to have been a series of tasks or benchmarks that were discussed as a good measure of human intelligence, right up until the machines exceeded humans on X or Y task.
Then we rapidly decided those tasks didn’t actually represent intelligence that well at all. The Turing test is one that springs to mind.
I don’t see large language models and transformer architectures getting us all the way to artificial general intelligence and I’m yet to be convinced that o1 and similar models are spending more time ‘thinking’ before they respond. So I’ve been poking around to see what else is out there to think about. Enter François Chollet and the ARC Prize.
On the Measure of Intelligence
Back in 2019, Chollet, creator of the ubiquitous open source Deep Learning package Keras, published On the Measure of Intelligence while a engineer and researcher at Google. In the abstract Chollet writes
We note that in practice, the contemporary AI community still gravitates towards benchmarking intelligence by comparing the skill exhibited by AIs and humans at specific tasks, such as board games and video games. We argue that solely measuring skill at any given task falls short of measuring intelligence, because skill is heavily modulated by prior knowledge and experience: unlimited priors or unlimited training data allow experimenters to “buy” arbitrary levels of skills for a system, in a way that masks the system’s own generalization power
It’s an interesting point and one that gets talked about very little outside of research circles. You can see this today with large language models; you will get a better biography of Halle Berry (very famous) out of ChatGPT and similar than you will of Kendra Vant (not very famous). And the arithmetic skills of most of the models fall off dramatically if you move from base 10 to base 11.
(Yes it amuses me too that Chollet refers to himself in the plural in the abstract of a single author paper but apparently some journals have very strict style rules about such things.)
The abstract continues
We then articulate a new formal definition of intelligence based on Algorithmic Information Theory, describing intelligence as skill-acquisition efficiency and highlighting the concepts of scope, generalization difficulty, priors, and experience, as critical pieces to be accounted for in characterizing intelligent systems.
It is this idea of skill-acquisition efficiency that is at the heart of ARC, the Abstract and Reasoning Corpus and now the ARC Challenge and Prize.
The ARC Prize
The Abstract and Reasoning Corpus is a set of puzzles that are reasonably easy for humans to solve but have proved extremely difficult for computers. In the first ARC competition, hosted on Kaggle in 2020, the winning team only managed to solve 21% of the puzzles in the final test set.

Stare at the above example for a minute or so and you will get the general idea but I really encourage you to take the time to pop over here and solve a couple of puzzles yourself to get a visceral feel it. And to ponder what it is you do and think about in order to solve each new puzzle challenge.
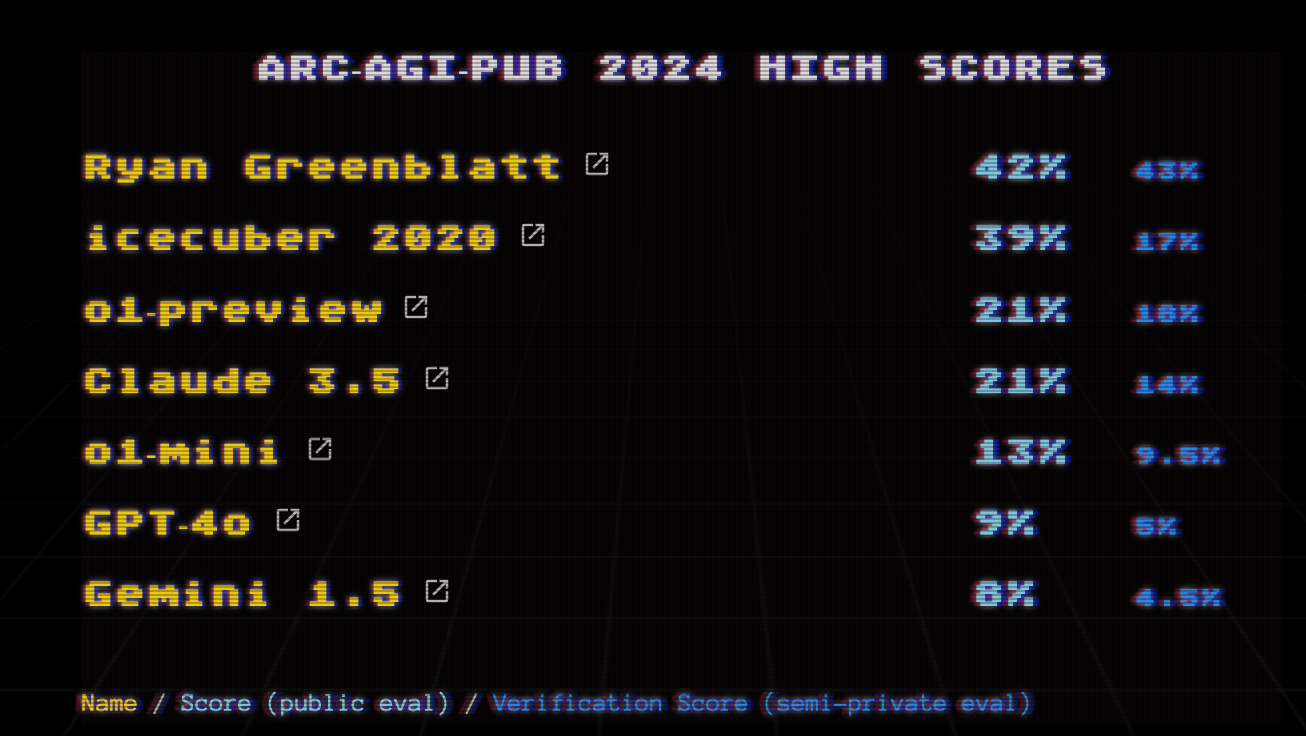
This year Chollet has teamed up with Mike Knoop, the co-founder of Zapier, to offer “a $1,000,000+ public competition to beat and open source a solution to the ARC-AGI benchmark.” Code submission closed in early November and the winners will be announced on Dec 6th. At present the leaderboard sits like this, with all the teams well off the Grand Prize Goal.

Importantly, the competition parameters specifically constrain the total run time of the proposed solution (to less than 12 hours) and allow no internet access. That of course rules out shipping the problems out wholesale to any of the commercially available LLMs.
Curious as to what would happen if you did? You are not the only one and there is a parallel activity stream and leaderboard with no constraints at all. Work here is not eligible for the prize but the results certainly are interesting.
Moving the field forward
One of the aspects of the ARC Challenge that I find particularly appealing is the emphasis on keeping solutions open source.
The spirit of ARC Prize is to open source progress towards AGI. To win prize money, you will be required to publish reproducible code/methods into public domain.
This is also reflected in the distribution of prize money for the 2024 competition. Assuming no team cracks the 85% barrier this year, there is actually more money on the line for the best paper ($50k) than there is for the highest scoring implementation ($25k).
While it isn’t surprising that research efforts in AI have narrowed over the past two years, it is concerning and I’m impressed by the focus Chollet and Knoop have on championing and supporting efforts to keep research open, vibrant and collaborative.
Beyond Dec 6th
With 2024 competition results due to be published in just a few days, it will be fascinating to read the papers and learn from the techniques employed by the top teams. Chollet is also apparently working on a new, harder benchmark set which I assume we will hear more about in 2025.
Definitely one to watch and, refreshingly, an area where there is plenty of deeply technical, nitty gritty content being written and recorded so you can learn alongside the leading teams.
I will leave the last word to the ARC Prize.

Nice article - very succinctly put. By complete coincidence I had been looking at the ARC tests recently but not the 2024 results. Thanks for highlighting them.