


AI and copyright
What you need to know before you build

Copyright in Generative AI feels more controversial and divisive than any aspect of the current frenzy around AI. The only other things that comes close to inspiring the same ire are deepfake porn and election misinformation. On my cynical days, the difference in heat seems to be that copyright questions put business models on the line rather than just raising the spectre of social harm.
I’m not a lawyer of any kind and certainly not an expert on the intricacies of intellectual property law. But I find this area both fascinating and important to many of the organisations I work in and advise.
No matter which side of the free use vs creator rights debate you come down on, as Andrew Ng mentioned in a recent opinion piece, the uncertainty and drawn out timelines for resolution are making it challenging to build or use Generative AI services with confidence So why is this all so hard for the lawyers to decide on? Why can’t we have a clear answer?
A preprint from Katherine Lee, A. Feder Cooper and James Grimmelmann ate up a recent rainy weekend for me very pleasantly. At 149 pages it is quite the long read! As always, if you find this once-over-lightly interesting, I encourage you to dive deeper and read the paper.
Think systems not models
As Generative AI models are embedded ever more extensively into working systems of many kinds, it is becoming more useful to talk about Generative AI systems and to think about them and analyse them holistically. This turns out to be particularly important in conversations about copyright because a lot of different actors make and interact with the Generative AI system at a lot of different points and in different ways throughout its lifecycle.
While the authors have a definition of ‘scale’ that will seem a little odd to the more technical readers, I think this paragraph gets the gist across although you may need to read it twice.
The other big enabler of today’s generative-AI systems is scale. Notably, scale complicates what technical and creative artifacts are produced, when these artifacts are produced and stored, and who exactly is involved in the production process. In turn, these considerations are important for how we reason about copyright implications: what is potentially an infringing artifact, when in the production process it is possible for infringement to occur, and who is potentially an infringing actor.
Talkin’ ‘Bout AI Generation: Copyright and the Generative-AI Supply Chain
You may be starting to get an inkling of how the paper ends up being 149 pages long!
The Generative AI supply chain
The Generative AI supply chain outlined in the paper has eight stages, all of which it turns out, can have murky and importantly debatable points about copyright.
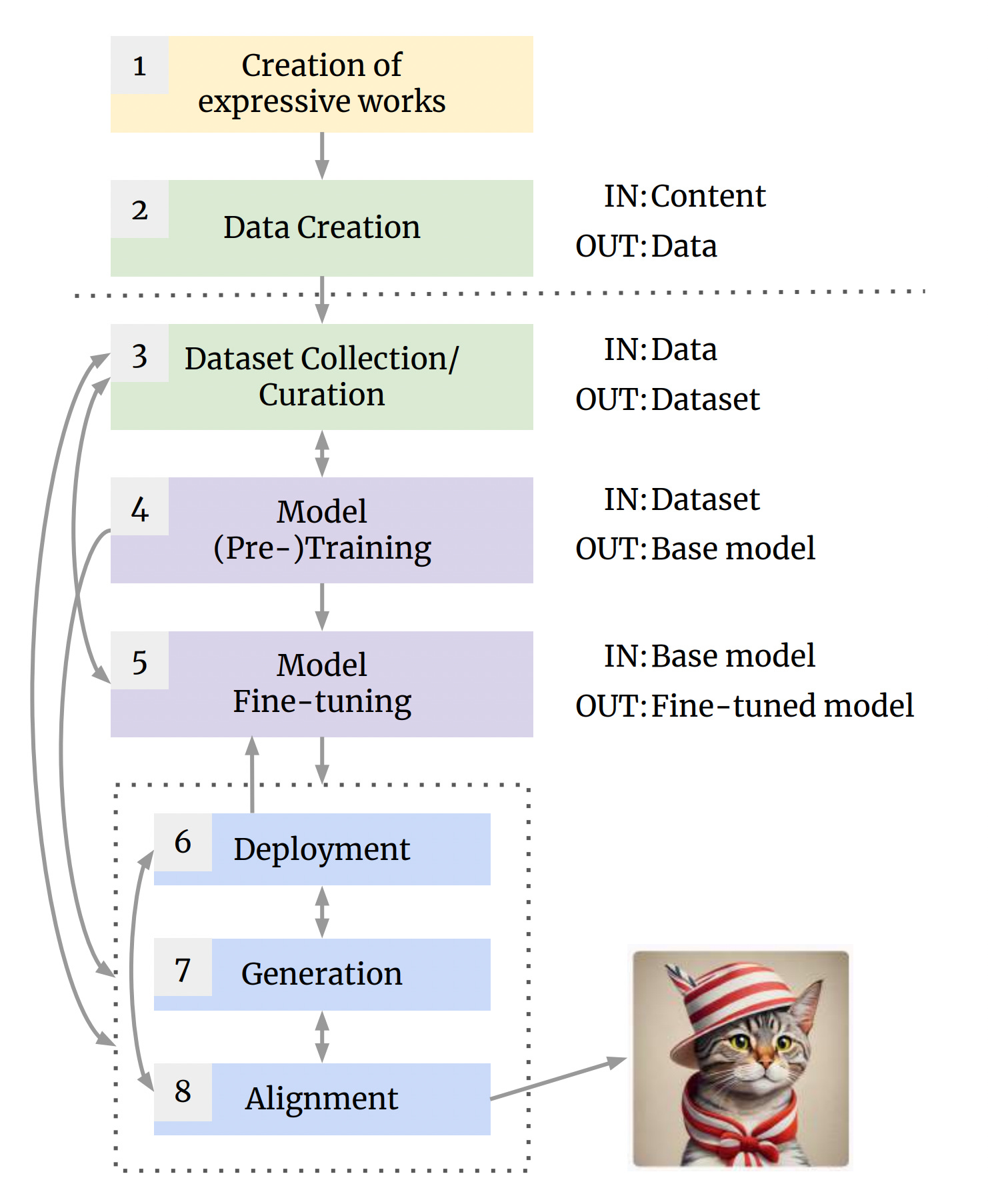
Here I’m going to highlight a few concepts I found particularly interesting / illuminating. I’m making the assumption that you are reasonably comfortable with the AI side of the AI supply chain. If that isn’t the case, apologies, this may not be the post for you. The paper itself does have a long section on an intro to AI which you might appreciate if you come more from the lawyer side of the house.
1 Creation of Expressive Works + 2 Data Creation
You might wonder, as I did, why step 1 and 2 are seperate. In typically precise fashion, the legal folks differentiate between the expressive work and the ‘computer readable’ rendition of that expressive work. However the ‘datafied’ version of the expressive work retains the copyright (if any) of the original. So no dodging anything by that particular step.
3 Dataset Collection and Curation
A key reason to clearly delineate this step, which involves gathering and filtering the data items that end up in a training collection, is that the dataset compilation process is frequently undertaken by a different entity than the one that trains a given Generative AI model. Hence more than one actor who might be considered liable for any copyright infringement. You can see how rapidly this gets complicated.
Just to get more complicated, because of the creative process of selecting data items to include in the dataset, a dataset itself can potentially be copyrighted.
In practice, however, it appears that most uses of training datasets are licensed — either through a bilateral negotiation or by means of an open-source license offered to the world by the dataset compiler.
I can definitely see this one tripping folk up. As a model trainer, you negotiate a license to use the dataset. My reading is that that is no guarantee that you actually have a license to use every data item within that dataset. Maybe you can pass on your liability to the dataset creator if someone can prove that the set contains a given disputed item? Maybe not.
4 Model (Pre-) Training
There are two interesting points that surface in this step. First, given how many decisions are made during the initial pre-training process - architecture, hyperparameters, etc - the pre-trained or base model might itself be subject to copyright. When exactly is there enough creativity in the process of model building for the training to be regarded as authorship?
(W)hen a training dataset is curated specifically for training a base model, the model may supplant the dataset as the relevant ‘work’ from the data curation process, just as a finished film is regarded as the ‘work’ rather than the (much larger) dataset of raw footage.
Second, it occurs to me that picking up and using a set of model weights from the internet becomes a delicate negotiation. Is there anyway to show the model lineage? How would you know if there had been one or multiple steps of pre-training / fine tuning, perhaps by multiple actors? Do some or all of them have creator claims?
It is helpful to make the base-/fine-tuned model distinction because different parties may have different knowledge of, control over, and intentions toward choices like which data is used for training and how the resulting trained model will, in turn, be put to use. A base-model creator, for example, may attempt to train the model to avoid generating copyright-infringing material.
However, if that model is publicly released, someone else may attempt to fine-tune the model to remove these anti-infringement guardrails. A full copyright analysis may require treating them differently, and indeed, may require analyzing their conduct in relation to each other.
6 Model Release and System Deployment
An interesting call out here to the system prompts that many hosted services insert for various reasons (including implementing guardrails with varying degrees of success)
For example, a generative-AI system deployed as a web-based application or as an API will often modify the user-supplied prompt before inputting it to the model. Several applications (ChatGPT, Bard, and Sydney, just to name a few) add additional instructions (i.e., application prompts) to the user’s input to create a compound prompt. The additional instructions change the behavior of the model output.
For example, providing the following prompts to a language model directs the model to behave differently: “I want you to act as an English translator, spelling corrector and improver . . . ” and “I want you to act as a poet. You will create poems that evoke emotions and have the power to stir people’s soul
I can see really tortuous conversations arising from system prompts in cases which try to assign liability to end users vs model providers. Particularly where users seek to override model controls that are designed to block the generation of specifically copyright violating content.
7 Generation
Now we’ve reached the complicated bit (you thought we were already there?!) when a human user can enter the picture and muddy the waters completely. As a user, you choose what you write in the prompt - simple, detailed, naive or deliberately manipulative.
You also make a choice, probably a reasonably conscious one, of which model to use, driven by access, cost and model capability factors. Voila, added uncertainty about your intent in each of those choices. Were you deliberately seeking out a model you knew to contain copyrighted data? Did you spoof the prompt to coerce the model to misbehave?
As we will see, characterizing the relationship between the user and the chosen deployed system is one of the critical choice points in a copyright-infringement analysis. There are at least three ways the relationship could be described:
• The user actively drives the generation through choice of prompt(s), and the system passively responds. On this view, the user is potentially a direct infringer, but the application is like a web host, ISP, or other neutral technological provider.
• The system is active and the user passive. On this view, the user is like a viewer of an infringing broadcast, or the unwitting buyer of a pirated copy of a book. Primary copyright responsibility lies with the deployed system, and possibly with others further upstream in the generative-AI supply chain.
• The user and the system are active partners in generating infringing outputs. On this view, the user is like a patron who commissions a copy of a painting, and the system is like the artist who executes it. They have a shared goal of creating an infringing work.
Additionally, the very long context windows now available on many models, facilitate users uploading entire books / movies as ‘context’ in the user prompt. So you could upload (wittingly or unwittingly) content that is not yet in the public domain. Is that completely on you? Do the model providers have to filter for copyrighted material in prompts? Would your content entirely let them off the hook if the same material was already in the training data and your prompt somehow caused it to float to the surface?
What can we learn from VCRs and Napster?
If you are old enough to remember them, cast your mind back to VCRs. You could tape a TV show and then replay it. You could rent a video from a video store and then play it … in your living room, or in a Scout Hall, gym, pub, etc. If replaying in general or in one or more of those venues specifically was a no no, was it you doing the law breaking or did the maker of the VCR bear some responsibility? This takes us into the space of contributory infringement and the Sony rule.
Contributory infringement is subject to the Sony rule. One who distributes a device capable of contributing to infringement — the classic example, from Sony itself is the VCR — is not liable for the resulting infringement, provided that the device is capable of substantial non-infringing uses.
Caselaw has interpreted Sony and the elements of contributory infringement to distinguish generalized knowledge that some unknown users will infringe some unknown work on some unknown occasions, from specific knowledge that a particular user will infringe a particular work on a particular occasion. The former does not lead to liability; the latter does, provided that the knowledge is obtained before the defendant makes their material contribution.
Thus, for example, Napster was not liable for copyright infringements committed by its users unless and until it was on notice of specific infringing songs that it failed to block.
…
Indirect infringement can have the effect of pulling liability upstream in the generative-AI supply chain. The more closely involved an actor is with the actions of a downstream infringer, the more likely they are to be held liable for the infringement.
This makes me wonder just how far upstream the ripples might travel. Dataset curators seem to potentially be caught at the squeeze point both ways - very close to the act of curating items that are copyright without the explicit right to do so AND potentially the fall peeps for the large and powerful model trainers, who might try to push liability upstream past themselves.
The multi actor conundrum
There are some great illustrative examples in the paper that I will carry around in my head going forward. Like the one about Calvin and Hobbs and content filters.

This is a great illustration of how hard it is to put meaningful guardrails around a large language model that wasn’t built with any inherent understand of or respect for human laws. All of that has to be bolted on after the fact and wow is it fragile. Yes I’m sure they’ve fixed this particular loophole, but you get my point about how whack-a-mole it all is.
From a copyright perspective who is at fault here? The user is being pretty darn persistent and sneaky. Does that let the LLM service provider off the hook? What if the sneaky user is a tech savvy 13 year old?
And if this is a kid using a fine tuned version of a Llama model hosted by HuggingFace built on top of a dataset like The Pile? Even non-legal folk like me can see how intricate and challenging this becomes.
Summary
As so often happens when you think something shouldn’t be taking as long as it is and then dive into trying to understand how it could possibly be that complex, I’m left realising what a deep pool I just dipped my toe into.
The idea that it is all fair use has always felt like self serving nonsense to me and knowing more about copyright hasn’t changed my mind on that.
But I have an expanded appreciation for why we’re all having to operate in limbo here while specific cases wind through the courts and create new precedent.
I tend to the side of creative rights and ‘you should pay for that’ and am increasingly concerned that we’re going to end up at ‘licensing fees for big players, nothing for individual creators’ because it’s all just too hard. Hopefully smart tech savvy lawyers like these authors will prove me wrong.
By the way, welcome to the 20 new subscribers since last edition. It’s lovely to have you here. And to the more seasoned subscribers, if you take 30 seconds now to share Data Runs Deep with someone you know who might like to read it, I would really appreciate it.
Image credit to Jakob Owens on Unsplash
The topic of Copyright and AI is one that many leaders need to be across. It is complex and brings risk. I enjoyed your write-up of this academic framework. I've recently written a similar piece for Board directors, focussing on the governance perspective. https://www.linkedin.com/pulse/new-risk-ai-intellectual-property-andrew-e-scott-gaicd-d1uoe/